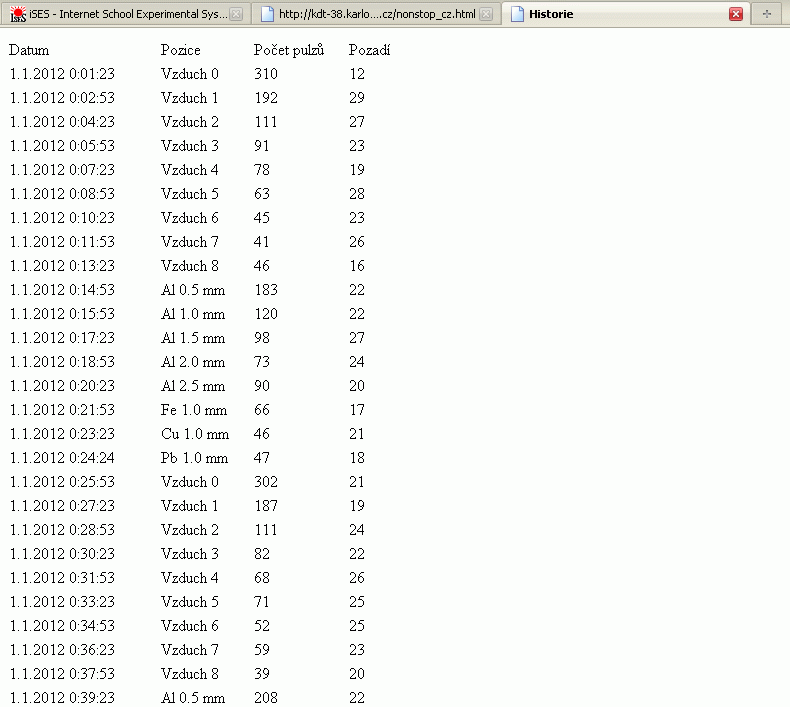
V této úloze předpokládáme základy práce s tabulkovými procesory typu MS Excel, Open Office Calc apod. Tyto znalosti si rozšíříme o další dovednosti. Po zkopírování dat (viz obr. 1) a jejich vložení do nového listu nejprve hodnoty můžeme prostorově roztřídit, a to pomocí funkce KDYŽ (IF) – viz obr. 2.
|
|
| Obr. 1: Vyskakovací okno s legendou a reálnými naměřenými hodnotami. |
|
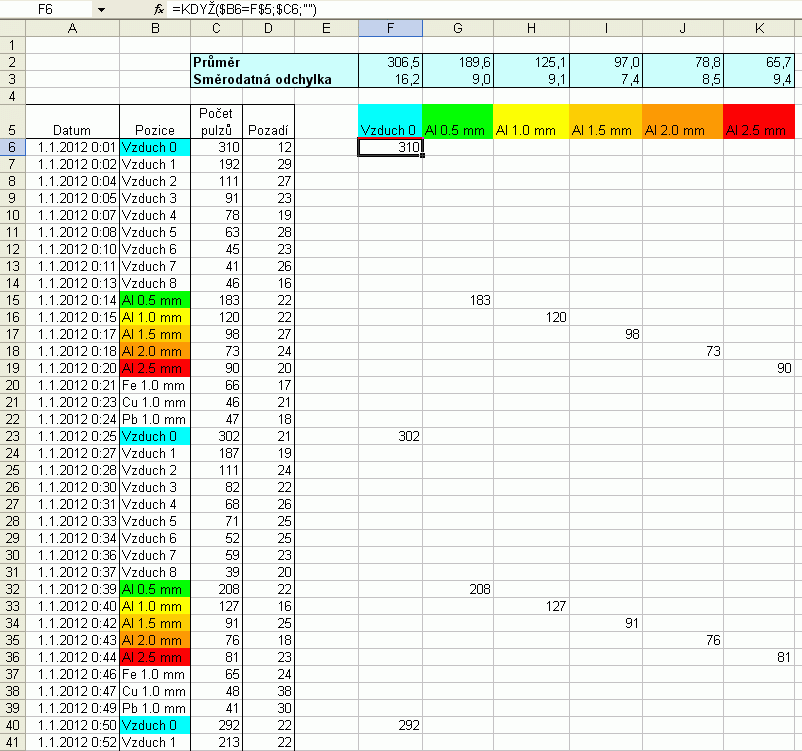
| Obr. 2: Předzpracování dat – prostorové roztřízení hodnot pomocí funkce KDYŽ. S využitím absolutních adres (přepínání klávesou F4) lze ostatní sloupce i řádky nakopírovat tažením buňky F6 za pravý dolní roh. Způsob adresování se liší podle verze Vašeho softwaru. Podívejte se na zadání funkce KDYŽ(podmínka;hodnota při splnění podmínky;hodnota při nesplnění podmínky). Dvoje dvojité uvozovky znamenají ponechat prázdnou buňku. |
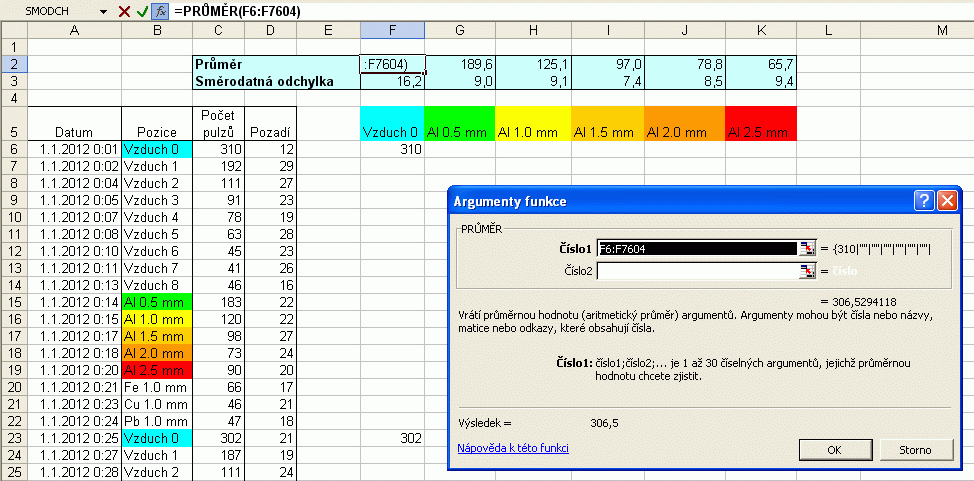
Ve sloupcích F až K necháme spočítat průměrnou hodnotu ze zvoleného počtu jednotlivých naměřených hodnot. Obdobně i směrodatnou odchylku. Pro výpočet můžeme využít ikonku fx, ve skupině statistických funkcí najdeme funkci PRŮMĚR i SMODCH, tzn. aritmetický průměr a směrodatnou odchylku a při zadání argumentů označíme myší oblast dat, z nichž se mají funkce počítat.
|
| Obr. 3: Ukázka okna pro nastavení funkce aritmetický PRŮMĚR. |
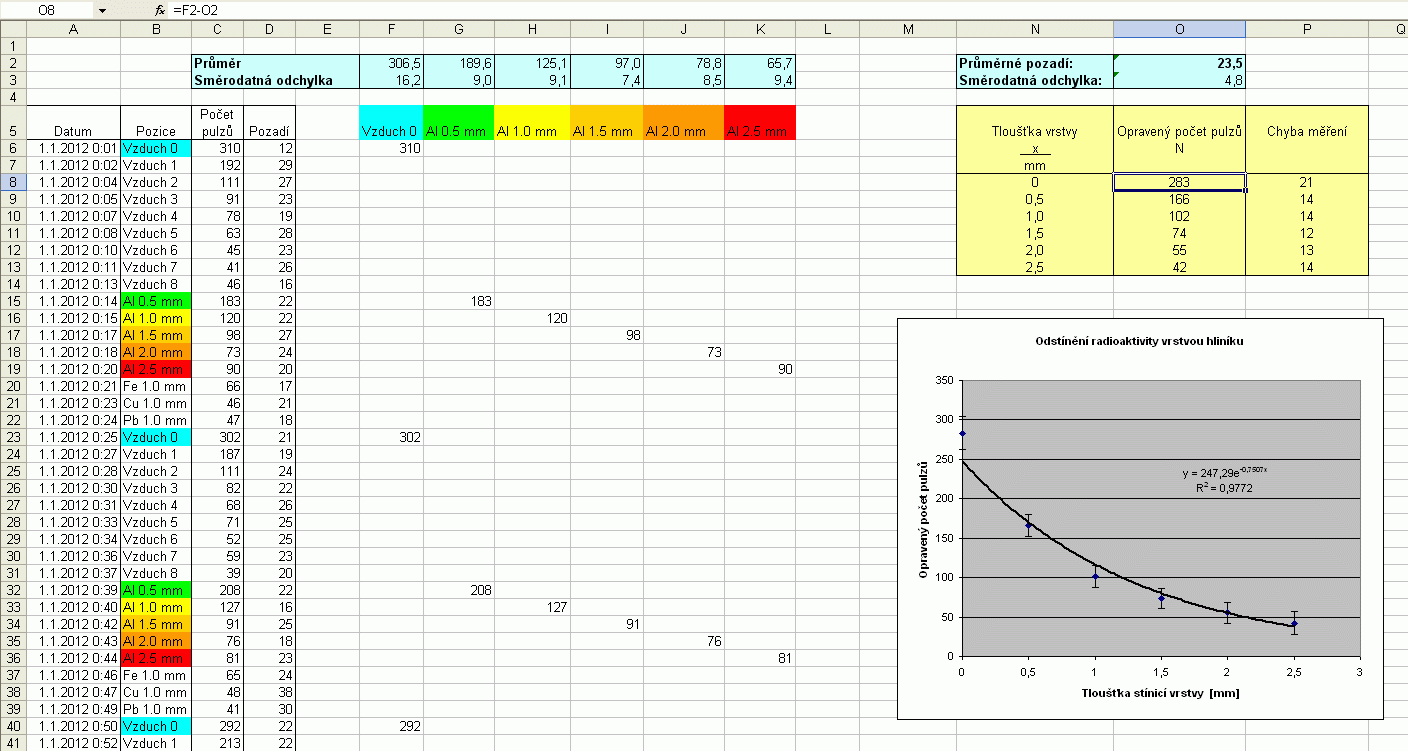
Obdobně necháme spočítat průměrnou hodnotu i směrodatnou odchylku pozadí, a to z hodnot ve sloupci D. V tabulce opravených hodnot na obr. 4 nakonec určíme opravené hodnoty jako naměřené průměrné hodnoty mínus průměrné pozadí (např. O8 = F2 − O2). Z teorie chyb měření plyne, že absolutní chyby v tomto případě můžeme sečíst (např. pole P8 = F3 + O3).
|
| Obr. 4: Ukázka grafu zkoumané závislosti s grafem očekávané závislosti. Chybové úsečky nám pomáhají posoudit přesnost a spolehlivost našeho měření i přes náhodný charakter tohoto měření. |
Na závěr necháme zobrazit graf, přidáme spojnici trendu a doporučujeme i chybové úsečky. Podrobnější návod zde.